

I’ve been refactoring quite a bit of legacy code recently. I love this kind of work because you get to architect new patterns and code pathways for future developers to use. Right past mistakes and make the future of the application just a bit brighter. My most recent refactoring involved converting an Enum based architecture to utilize Rail’s Single Table Inheritance setup. So what does it take to move from one architecture to another? Keep reading to find out strategies that I use to help keep bugs to a minimum while ensuring that end-users experience zero downtime.
For major architecture refactors, there are a few steps I take to determine what the desirable end result is. Do you want to modify an existing feature? Convert an existing feature into another? Is this a brand new feature? These high-level questions about the purpose behind the refactor help guide you in making decisions that lead to a successful delivery.
Assessing the challenge
For the purposes of our case, let’s assume we’re dealing with the following goal.
Situation
An enum column on our table has gotten out of control and we need to move to a more
organized architecture. We’ve decided something needs to change now let’s figure out what we
want the new application to look like.
Here’s a little bit of background visualization on our application:

class Restaurant
has_many :beers
end
class Beer
belongs_to :restaurant
enum beer_types: %i(porter stout hefeweizen)
end As time goes on, the pattern above perpetuates itself and developers keep adding more and more beer_types. This isn’t necessarily a bad thing except each of these types has special processing logic. This means every time we add a new beer type at the very least the #is_on_tap?, #preferred_glass, and #serving_temperature methods below become just a little bit more complicated.
class Beer
belongs_to :restaurant
enum beer_types: %i(porter stout hefeweizen)
# Only certain beers are on-tap
def is_on_tap?
return true if porter? || stout?
false
end
# New shipments of beer aren't cold initially
def preferred_glass
case beer_type
when porter? then glass_1
when stout? then glass_2
when hefeweizen? then glass_3
end
end
def serving_temperature
case beer_type
when porter?, stout? then "45-50"
when hefeweizen? then "40-45"
end
end
end As you can see above, using enums leads to more and more conditional statements. To make matters worse these conditionals end up living in the base Beer model further cluttering its domain. Now you could move these into a concern but that is essentially equivalent to sweeping the dirt elsewhere. We still have a pattern that left unchecked will lead to bloat in our application. Like we discussed above, our entire purpose is to make this better for the next developer so let’s do that by determining the preferred outcome through some introspective questioning.
“When the future cost of doing nothing is the same as the current cost, postpone the decision. Make the decision only when you must with the information you have at that time.”
- Sandi Metz, Practical Object-Oriented Design in Ruby: An Agile Primer
Q: Do we want each type to have its own database table or share a single table?
A: This is a fundamental question when deciding upon a refactor approach. Currently, we have a single database table Beers. For each type to have its own database table we would need to implement polymorphic associations which consist of a table per type and a join table that contains an id and type for matching. While a more future-proof solution, this approach has a more complicated migration strategy as the current Beers table now needs to be split up into several different tables with properly joined associations for any existing records.
The other option is to reuse the existing Beers table and allowing it to serve as a storage location for multiple types. This is accomplished via Single Table Inheritance. In this implementation all we need is a new type column on the existing table and to backfill existing type data. The thinking here being, if you don’t need full blown polymorphic associations and inheritance will work then stick with the solution you know will work today. Additionally, we gain many of same benefits of polymorphic associations like type specific classes and greater composition opportunities with less work. The strategy is much simpler and for the purposes of this article is just enough to accomplish our desired outcome.
Preferred Outcome
Beershould stop relying on of thebeer_typecolumn and instead utilize STI’stypecolumnBeershould have a class for each type of beer to help separate the different responsibilities between the types- Beer’s
beer_typecolumn should eventually be removed completely in favor of the new method. - New
BeerSTI type models should share common responsibilities through composition (e.g. modules)
Planning the migration strategy
Now that we have an idea of what we’d like to accomplish, we’ll want a step-by-step strategy for doing it. This is important to avoid issues of application downtime as well as ensuring that your approach is sound.
Downtime example
In a single deployment a new developer adds both a new column and the code that depends on it. During deployment there is a period of time where the new code is live before all the migrations have run. It is during this interval of waiting on the database that any users accessing the application will receive 500 errors from the new feature.
Something to note here is that each of the stages below is deployed separately from one another. Let me repeat that. Each one of these stages needs to be a separate deploy. The reason for this is when you add code that depends upon a database column existing but the migration hasn’t ran yet the code cannot function properly. This leads to application errors and downtime. By adding a new column in one deploy and then on the subsequent one adding the code that uses the column there is no risk of exceptions.
Here’s a brief overview of our strategy with more details in each of the upcoming sections:
- Add a new database column called “type” to enable STI on the Beer Table
- Sync all new Beer records by ensuring that their “type” is filled out. Additionally, backfill existing Beer data’s type column.
- Abstract and separate the type concerns. This means adding type specific logic into each of the new STI models. Additionally, disallow using the old Beer.beer_type column.
- With the application relying completely on the new column and the old column disabled we can finally drop the
beer_typecolumn and any supporting code.
Phase 1: Add a new database column called type to the Beer table
This is the easiest phase. There isn’t any major changes or concerns with locking the database of existing Beers. All we need here is a simple migration to add the type column.
Note
One thing to avoid at this point is adding anot: nullconstraint to the new type field. The reason for this is because type doesn't have valid data yet and setting a constraint will only force it to throw exceptions everywhere.
The migration below can also be generator from the command line with rails g migration AddTypeColumnToBeers type:string.
class AddTypeColumnToBeers < ActiveRecord::Migration[5.0]
def change
add_column :beers, :type, :string
end
endPhase 2: Sync all new Beer records and backfill existing records
Now that we have our new column deployed we can start using it. The first thing we’ll want to do is ensure that all new Beers use the new setup. We can accomplish this with a simple before callback that allows us to keep the new column in sync with the old. I prefer to place these into concerns with comments detailing that they should be removed at a later date.
# This should be removed once Beer::question_type is not longer necessary
module SyncBeerType
extend ActiveSupport::Concern
included do
before_save :sync_type
end
def sync_type
self.type = beer_type.to_s.classify
end
end
class Beer
include SyncBeerType
belongs_to :restaurant
# ... other methods ...
endWith this in place, all future Beers also set a proper type value.
Laying some ground-work for our STI implementation
Next, we can start creating the type specific models for each Beer type. This is good preparation work for when we have confidence that our database’s type column is always filled out (phase 3). We don’t actually need any logic in these yet but they are necessary for STI to function properly.
class Porter < Beer
end
class Stout < Beer
end
class Hefeweizen < Beer
endYou may have noticed above that each of these inherit from the original Beer class. This makes each of them behave the same way the old code does while preparing us to start abstracting type specific logic into the individual Beer type models in the next phase. Additionally, single table inheritance requires a each child class to inherit from the parent base class.
Adding new STI scopes to the Restaurant model
Remember our dinky little Restaurant model? All it does is say a Restaurant has many Beers. Now with STI setup we can add some additional helper associations to improve chaining and querying in ActiveRecord.
class Restaurant
has_many :beers
has_many :porters, class_name: Porter
has_many :stouts, class_name: Stout
has_many :hefeweizens, class_name: Hefeweizen
endWe can now chain queries like Restaurant.first.porters to see all of
a given Restaurant's Porter beers.
Backfill all existing Beer database records
The last part of this phase is to backfill the existing data. We can do this with a migration that updates batches of records at a time. The reason for using batches is that if you have say hundreds of thousands of Beer records trying to update them all at once might leave your database locked up. Again this could lead to downtime for your users which we’d like to avoid here.
All migration should be reversible
A good guideline for migration is to ensure thatrails db:rollbackworks without issue. When code is anticipated in the future to be removed but is required for a migration to work, like below, re-implementing the logic directly in the migration allows for the migration to always work. This is regardless of the application's implementation.
class BackfillBeerTypeColumnWithExistingEnumData < ActiveRecord::Migration[5.0]
# Disables the standard Rails transaction that is wrapped around each
# migration. For this migration we're pretty safe in that we're updating in
# batches using an update_all statement.
disable_ddl_transaction!
# We are re-implementing this class here for a good reason! Eventually
# Beer's beer_types will be completely removed from the application meaning that
# if we just used Beer.beer_types in the below code it wouldn't work. This
# situation would only occur for new development environment setup's of the
# application. It is a best practice to keep your migrations as reversible as possible.
class Beer < ApplicationRecord
enum beer_types: %i(porter stout hefeweizen india_pale_ale brown_ale saison pilsner lager)
end
def up
Beer.beer_types.keys.each do |beer_type|
update_beer_type(beer_type)
end
end
def down
Beer.beer_types.keys.each do |beer_type|
nullify_beer_type(beer_type)
end
end
private
def update_beer_type(beer_type)
type = beer_type.classify
Beer.send(beer_type.to_sym).where(type: nil).in_batches do |beer_batch|
beer_batch.update_all(type: type)
end
end
def nullify_beer_type(beer_type)
Beer.send(beer_type.to_sym).where.not(type: nil).in_batches do |beer_batch|
beer_batch.update_all(type: nil)
end
end
endAdditionally, at this point we can really lock down the type column by adding a
database level not: null constraint. This prevents new records from
being created or updated if the type column is empty.
class AddNullConstraintToTypeColumnOnBeersTable < ActiveRecord::Migration[5.0]
def change
change_column_null :beers, :type, false
end
endOnce we’ve deployed the above phase, we can have complete confidence that all of
our Beer’s have their type column filled out. Let’s move onto the phase
where we start making big changes.
Phase 3: Abstract out and separate type specific responsibilities
Now that we have a fully working STI architecture we can begin to move logic into type specific locations. One of the largest benefits of STI is it allows better organization of logic based on type.
Before we jump into that you’ll want to spend some time at this point ensuring that all code branches that create new Beer records in the database also supply the proper type. The reason for this is that we also want to move away from relying on the SyncBeerType’s callback and instead have the system work properly. A quick example of a controller action change might look something like this:
# Original controller
class BeersController < ApplicationController
def create
@beer = Beer.new(beer_params)
# Assuming that we are sending json responses
if @beer.save
render json: { success: true }
else
render json: { success: false}
end
end
private
def beer_params
params.require(:beer).permit(:id, :name)
end
end
# Updated controller to account for Beer::type
class BeersController < ApplicationController
def create
@beer = Beer.new(beer_params)
# OR constantize the type
@beer = beer_params[:type]
.classify
.safe_constantize
.new(beer_params)
# Assuming that we are sending json responses
if @beer.save
render json: { success: true }
else
render json: { success: false}
end
end
private
# Add type to the strong parameters
def beer_params
params.require(:beer).permit(:id, :name, :type)
end
endOnce, you changed all the branches for Beer records being created or updated you can begin to break down some of the current Beer class logic into specific types.
class Porter < Beer
def is_on_tap?
true
end
def preferred_glass
glass_1
end
def serving_temperature
"45-50"
end
end
class Stout < Beer
def is_on_tap?
true
end
def preferred_glass
glass_2
end
def serving_temperature
"45-50"
end
end
class Hefeweizen < Beer
# Note: Because we inherit from Beer and only need the default implementation
# we can rely completely on the parent's #is_on_tap? method
def preferred_glass
glass_3
end
def serving_temperature
"40-45"
end
end
class Beer
belongs_to :restaurant
enum beer_types: %i(porter stout hefeweizen)
# Inheritors of Beer can override this method
def is_on_tap?
false
end
# This method can now utilize the template pattern ensuring that all
# subclasses follow the interface contract set
def preferred_glass
raise NotImplementedError, "#{self.class} cannot respond to: #{__method__}"
end
# Another template pattern to ensure #serving temperature is defined in subclasses
def serving_temperature
raise NotImplementedError, "#{self.class} cannot respond to: #{__method__}"
end
end Looks pretty good so far. We’ve moved much of the conditional logic out of Beer and instead allowed each type to just know what it is capable of. Since Beer is now the base class, or parent class, it serves as the default implementation for method definitions. You can see one of the benefits above which is the template method pattern.
Template method pattern
"In software engineering, the template method pattern is a behavioral design pattern that defines the program skeleton of an algorithm in an operation, deferring some steps to subclasses."
- Wikipedia, Template Method Pattern
Let’s take a look at a direct benefit of STI. With the old style of using enums we’d have to write type-checking code like the below snippet:
beer = Beer.find(params[:id])
if beer.porter?
beer.pour_porter
elsif beer.stout?
beer.pour_stout
elsif beer.hefeweizen?
beer.pour_hefeweizen
endWith the new single table inheritance architecture, we can trust the object to know how to respond to the interface from the base class (Beer). This allows any Beer object stand in for one another. We could now re-write the above like this:
# Using the base class of Beer, allows us to lookup
# any available beer that matches the id
beer = Beer.find(params[:id]) #=> SELECT * FROM beers WHERE id = 1 LIMIT 1
beer.pour
# If we know the type in the sent controller params we
# could also write something like the following to directly
# query by the STI model's type.
# (assuming that params[:type] #=> "Stout")
beer = params[:type]
.classify
.safe_constantize
.find(params[:id]) #=> SELECT * FROM beers WHERE type IN ('Stout') AND id = 1 LIMIT 1
beer.pourDrunk ducks
Because all future types of Beers inherit from the base class of beer, they all respond to the same interface of methods. This enables us to write duck types or have any type of Beer object stand-in for another. This avoids the necessity of type-checks. Quack, quack.
Additionally, single table inheritance allows us to call the model directly and ActiveRecord knows to properly build sql to query the specific type (see the raw sql below).
beer = Porter.first #=> SQL: select * from beers where type = 'Porter' LIMIT 1
beer.pour #=> Pours a Porter
# Customer would like another one
beer = Stout.first #=> SQL: select * from beers where type = 'Stout' LIMIT 1
beer.pour #=> Pours a StoutReject the old column
Rails 5 has a built-in way of manually disabling columns in ActiveRecord. This is a great trick for simulating in advance what the application will function like once phase 4’s dropping of the beer_type column occurs. Not only does this allow you to modify your test suite to accommodate the removal of the column but it also prevents the application from holding onto the rejected column in memory. For example, having this step occur one deployment before phase 4 prevents the application from using the column in any manner.
What I like to do here is modify the module used for syncing to instead ignore the column to be dropped in the upcoming deployment.
module SyncBeerType
extend ActiveSupport::Concern
included do
self.ignored_columns = %w(beer_type)
end
endDuck Typing
"Whenever possible, you should treat objects according to the methods they define rather than the classes from which they inherit or the modules they include."
- http://rubylearning.com/satishtalim/duck_typing.html
While ignoring the beer_type column in ActiveRecord prevents it from being visible, there are still several enum predicate methods that can be used. The methods I’m referring to are porter?, stout?, hefeweizen?. These essentially perform type checks, which for our purposes, we want to instead favor duck typing.
Between Phase 3 and Phase 4, other developers may continue to use these predicate methods. One way to avoid this is to override the predicate methods to signal to developers that they are no longer supported. Similar to ignoring the ActiveRecord column above, this allows us to prepare for the next phase without having to update other developer code in the interim. We can also leave a helpful message to encourage the use of duck typing.
module SyncBeerType
extend ActiveSupport::Concern
included do
self.ignored_columns = %w(beer_type)
# New Error type
UnsupportedMethodError = Class.new(StandardError)
# All predicate methods follow the same pattern. We could probably
# use something like method_missing here but for the sake of explictness
# I've written each of them out.
#
# __method__ is just a magic variable that contains the name of the current
# method. (e.g. porter?, stout?, hefeweizen?)
def porter?
unsupported_method(__method__)
end
def stout?
unsupported_method(__method__)
end
def hefeweizen?
unsupported_method(__method__)
end
# This looks complicated but actually just raises the new Error type
# and prints a message that includes the calling method's signature.
def unsupported_method(method)
raise UnsupportedMethodError, <<~EXCEPTION
#{method} is no longer supported. If you need to know a Beer's type please use `object.is_a?(some-type)`
A more ideal approach is to have a Beer object respond to a message via duck typing.
EXCEPTION
end
end
endAdditionally, at this point we can remove the bit of code within the old Beer model that specified the enums:
class Beer
belongs_to :restaurant
# Remove the line of code below as it is no longer necessary
enum beer_types: %i(porter stout hefeweizen)
# ... additional logic ...
end The assumption at this point is that all code will be writing to only the new type column and that any old logic will no longer work with the old beer_type column. Also by using the same concern we don’t need to update any of the Beer subclasses include statements.
Share common behavior through Composition instead of Inheritance
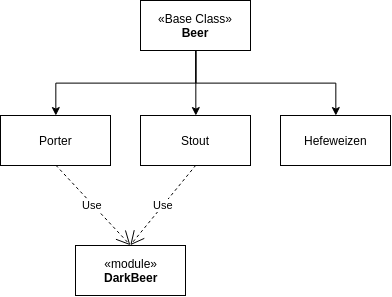
Something else we could start doing here is abstracting out common logic into modules. For instance both the Porter and the Stout are served at the same temperature. They also both happen to be dark beers. From this we can create a DarkBeer module that is includeable in any future dark beer models.
Inheritance vs. Composition
Use Inheritance for is-a relationships. A Stout is-a Beer. Use Composition for has-a relationships. A Stout has-a DarkBeer color.
- Sandi Metz, Practical Object-Oriented Design in Ruby: An Agile Primer, Paraphrase
module DarkBeer
extend ActiveSupport::Concern
def serving_temperature
"45-50"
end
end
class Porter < Beer
include DarkBeer
def is_on_tap?
true
end
def preferred_glass
glass_1
end
end
class Stout < Beer
include DarkBeer
def is_on_tap?
true
end
def preferred_glass
glass_2
end
endYou may at first be tempted to create another layer of inheritance with something like Beer > DarkBeer > Porter. While this technically would work, it also ties us to the strict hierarchy which may or may not be the right abstraction at this point. This increases upkeep costs of maintaining the codebase. Using composition with modules allows us to reuse behaviors, like DarkBeer, without ties specific types to a strict interface that inheritance implements. Sandi Metz explains the pitfalls of inheritance best in the below quote.
"Shallow, narrow hierarchies are easy to understand. Shallow, wide hierarchies are slightly more complicated. Deep, narrow hierarchies are a bit more challenging and unfortunately have a natural tendency to get wider, strictly as a side effect of their depth. Deep, wide hierarchies are difficult to understand, costly to maintain, and should be avoided."
- Sandi Metz, Practical Object-Oriented Design in Ruby: An Agile Primer
At this point, you can continue on abstracting common logic and methods while improving the overall structure of the new STI architecture. Once, you feel good about it (less is more here) you can move onto the last phase dropping the old enum beer_type column
Phase 4: Drop the old beer_type column
We did it! We’ve abstracted common code logic into modules and placed type specific logic in its respective model. We have a database that contains accurate data and all future record creations write to the proper column. Additionally, we have disallowed writing to the old column which allows us to safely remove it from the system. This also means that the system is prepared to function without the column existing. So the only things left are to write a migration to drop the beer_type column and remove the SyncBeerType.
class DropBeerTypeColumnFromBeers < ActiveRecord::Migration[5.0]
def change
drop_column :beers, :beer_type, :string
end
end
# Remove the module
module SyncBeerType
extend ActiveSupport::Concern
included do
self.ignored_columns = %w(beer_type)
end
end
# Remove the individual includes from Porter and Stout
class Porter < Beer
include DarkBeer # Remove this line
# ... more logic ...
endTL;DR; on the above strategy
Here’s a brief overview of various deployment phases to ensure a smooth migration strategy:
- Add new column called “type”
- All new Beer records write to the “type” column and all existing Beer records are backfilled with “type” data
- Abstract and organize common logic between types. Reject writing to the old column in preparation for removal.
- Drop the old beer_type column.
And there you have it. A safe and zero downtime approach to moving from an existing Enum column to Single Table Inheritance. Enjoy, responsibly!

Is there something you find useful while migrating an application’s architecture? Did I miss an important step or trick you’d like to see added to this post? Shoot me a comment below and thanks for reading!
How to call Pry from within a SimpleDelegator Decorator
Override an ActiveRecord attribute value while using the same getter method
Join the conversation